大模型时代下的数据存储与分析该如何处理?有没有已经落地的应用实践?
为探讨这些问题,近日,阿里云联合 Zilliz 和 Doris 举办了一场以《大模型时代下的数据存储与分析》为主题的技术沙龙,其中,阿里云对象存储 OSS 上拥有海量的非结构化数据,Milvus(Zilliz)作为全球最有影响力的开源向量数据库项目 、Doris(飞轮科技)作为热门的数据分析项目,都积累了丰富的非结构化数据处理和分析的最佳实践。
沙龙现场,Zilliz 运营与生态负责人李晨进行了名为《向量数据库:大模型的记忆体》的主题分享。

受大模型催化,向量数据库方兴未艾。与传统数据库相比,向量数据库面向高维度向量,可以更好地处理图像、音频和视频等非结构化数据。李晨主要介绍了向量数据库的基本原理、应用场景和演进方向,以及 Zilliz 在此方向中的积累和心得。
他表示,向量数据库是 AIGC 大模型的重要补充,是提供准确可靠、高度可扩展的长短期“记忆”的关键载体,其在 LLM领域的应用主要可以分为以下 6 类:管理私有数据和知识库、为大模型提供实时数据更新、实现大模型的个性化和增强、提供智能体的记忆、保存大模型的处理结果、构建更复杂的AI系统。当然,这其中离不开一个新的程序开发应用范式—— CVP Stack。
在 CVP Stack 中,C是以 ChatGPT 为代表的大模型,它在 AI 程序中充当中央处理器的角色;V 代表 Vector Database,即以 Zilliz Cloud 和 Milvus 为代表的向量数据库,为大模型提供知识存储;P 代表 Prompt Engineering,各环节通过 Prompt 的方式进行交互。
相比单模型架构,CVP 架构在灵活性、可扩展性、实时性、成本四个维度都有明显优势。最关键的原因是,在 CVP 架构中,领域知识可以用数据入库的形式进行更新,而非重新训练或微调模型,向量数据库是该架构的重要组成部分。这其中一个典型的应用实践就是 OSSChat(https://osschat.io/chat),它用于解决开源项目文档冗长、不易查找等问题,目前已经支持几十个主流的开源项目。
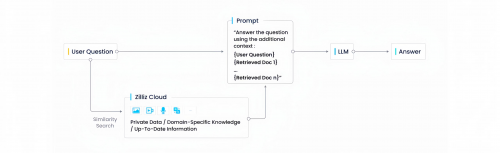
此外,为了进一步降低应用构建成本,提供标准化组件,Zilliz 已与全球头部大模型生态完成了 C-V 间对接。2023 年 3 月,Zilliz 作为 OpenAI 首批向量数据库合作伙伴,完成了 Milvus 与 Zilliz Cloud 插件化集成,作为官方推荐的向量数据库插件提供给广大应用开发者。同时,Zilliz 还与 LangChain、Cohere、LlamaIndex、Auto-GPT、BabyAGI 等热门项目进行了深度集成。值得一提的是,Zilliz Cloud 已经正式在国内提供云服务,也在今年7月份官宣了和阿里云的合作,相信在双方的努力配合下,一定可以让用户享受到更好的产品和服务。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
关键词:










